
Course Overview
Data Curation II examines a broad range of practical and conceptual issues in the field of data curation. As the second in a sequence of courses offered at the UW iSchool, Data Curation II offers an in-depth study of the semantics and structure of data as an information object used in scholarship and society. This knowledge will be useful when applied to practical activities such as data normalization, cleaning, or packaging for sharing and reuse. We will also pay particular attention to the repository architectures (technical design) and information infrastructures (technological and social connectivity) that constrain and afford data access. Throughout the quarter we will draw on research, case studies, and practical working examples in order to examine key challenges in the field. See the video below for an extended introduction to the course structure this term.
Graduate School and a Pandemic
The last time this course was taught, it was the very beginning of the pandemic for those of us in the United States. No one knew what was going to happen but we knew that life was going to be different. Professor Weber wrote this to his Spring 2020 class:
There is no easy way to put this - its going to be a challenging quarter. I usually put a note in my syllabus that says something along the lines of "...coursework occasionally needs to take a second, third, or fourth priority in your life. All of us have commitments that exceed the expectation of being fully present each week, and I don't expect you to be operating at 100% engagement each day." Even this qualification seems out of touch given the current climate we are operating in for the Spring 2020 quarter. There will be demands on your time, attention, emotions, and cognitive ability to engage with substantive material over the next 10 weeks. There are many unknowns that we are each managing. I have relaxed my own personal expectations for this quarter, and I encourage you all to do the same. This doesn't mean that I will give anything short of 100% effort to delivering a high quality course, but lets operate with a healthy and charitable amount of good will towards each other and towards ourselves for the next 10 weeks.
I encourage you all to read my colleague Anna Hoffman's very personal and incredibly eloquent take on the challenges that we face in the quarter that lies ahead.
In one year a lot has changed and a lot hasn’t. All I really want to say is that I plan to be flexible, understanding, and to give as much as I possible can to this class. Please reach out to me with feedback about workload, individual needs, and struggles (and of course let me know what is going well!) and I will see where we can make changes.
Accessibility
-
I have turned Professor Weber’s original course book into this website on his recommendation and with his permission. There will be minimal material on the Canvas site. I hope that this makes skimming and digesting the material much easier, and it provides a sustainable resource that you can return to at any time in the future (and is publicly accessible). The course content will remain accessible to you regardless of your being enrolled as a student at UW.
-
There will be a short and hopefully helpful lecture each week either recorded by Professor Weber or myself, but the majority of the substantive content is in the form of pages on this website and as links to articles and other websites.
-
On a week to week basis circumstances may change for how and when you are able to access course materials. I am attempting to provide PDFs or links to freely available web resources for all readings that are assigned. These will not require you to have any kind of remote VPN or UW affiliated credentials to access. If you cannot, for any reason, access course materials please be in touch and I will figure out a way to get the material to you.
Workload and Expectations for Engagement
My expectations for you are that you engage with the content, meet with me regularly either individually or as a group, and keep me up-to-date on your progress. I know this may sound vague as a participation rubric, but If you meet these criteria you will receive full participation points. I will reach out to you if I am concerned about your level of participation.
The Protocol project that makes up a substantive amount of work at the conclusion of this quarter will have some examples from previous courses. The pandemic may place barriers on equaling the depth or scope of content that student’s in previous courses have had the freedom to accomplish. See my previous comment about relaxing expectations and demands of ourselves - this doesn’t mean that we should give anything less than what we are capable of - but I understand the challenges we are all facing.
Assignments and exercises have listed deadlines, but these are negotiable. As lited in the syllabus, I request that you reach out to me at least 24 hours prior to a deadline if you need to make alternate arrangements. You can turn in assignments at any time throughout the quarter and I will provide feedback as is necessary for you to understand and contextualize the goal of the assignment. I have two requests related to this policy:
-
Please make an earnest effort to keep up with work. The course is designed to take advantage of progressive knowledge gain. Practice or exercise in one week often is the baseline for starting an assignment the next week. There may be times when you need to make alternate arrangemnets, but give the stated timeline your best effort.
-
Please try to communicate when a priority deadline is not realistic for you to meet (my email is
norlab@uw.edu). This should be before the deadline has passed if at all possible. You do not need to explain why. If you are falling behind and I havent’t had have any communication from you I may reach out with an email. Please don’t interpret this as any form of pressure other than my expressing a concern.
How this class is organized
There are two aspect of this class that will require your time and attention.
- Class sessions (Weeks 1-10) follow the typical structure of an iSchool online course.
- Your
Protocolassignment has a weekly activity or assignment that you will complete (either as a group or individually). The assignments vary in terms of the effort that will be required - some are involved and will take hours to complete, others are simple readings that will help you think about your protocol.
Weekly content: each week of the course will consist of four or five (depending on the week) components: 1. Written content on the website; 2. Readings (required and optional); 3. Recorded lectures; 4. Exercises; 5. Assignment (a piece of your final deliverable).
- Written website content is equivalent to an informal textbook chapter. The content is an extended narrative where Professor Weber and I attempt to explain, define, and introduce concepts related to data curation. You should read these thoroughly - but also feel free to return to these as a reference resource in the future.
- Readings are meant to reinforce concepts and offer practical applications or extensions of the concept / topic we are discussing each week.
- Short lectures reinforce important points from the weekly module and provide an opportunity to present more dynamic content. Where possible I will provide links to slides that are used, and all lectures will be accessible as an MP4 that you can view on any device or with any program of your choosing.
- Most weeks there will be an exercise in which we ask you to engage with open data in some practical way. This might include restructuring a dataset, using a tool, or practicing some skill that is applicable to our weekly topic. A list of exercises are found below. Note that in some weeks there will simply be a demonstration that does not require you to do anything other than watch and engage with the demo. There will be a discussion board on Canvas for each exercise. Please post your work there. For many of the exercises there are multiple “correct” ways of completing the task and being able to see how classmates interpret the instructions will be valuable as you work through the quarter. Please feel free to engage in discussion of the exercises on the canvas site (in a respectful and supportive manner of course). Exercises are graded as completed (1 point) or not completed (0 points).
- Most weeks I will post an assignment activity that you or your group are to complete. The requirements and effort for completing these will be variable. These assignments are in service of a final project deliverable. By combining these different assignments you can create a rather comprehensive protocol that will be valuable to your professional portfolio (more below). You can share the protocol assignments with me in advance of our weekly meeting for feedback. I will give you explicit directions on how to do this.
Topic Overview
| Week | Topic | Exercise | Protocol Assignment |
|---|---|---|---|
| 1 | Class Introduction | Introductions | None |
| 2 | Tables, Trees, and Triples | Cookie Recipes | Data Pitch |
| 3 | Tidy Data | Messy Recipe Data | Definition, Scope, Audience |
| 4 | Data Integration | 311 Data | User Stories |
| 5 | Data Packaging | Data Curator Demo | Data Collection Policies |
| 6 | Repository Architectures | None | None |
| 7 | Data Acquisition, Search, and Discovery | APIs | Data Transformations and Quality |
| 8 | Metadata Application Profiles | None | Metadata Application Profiles |
| 9 | Ontologies and Linked Data | None | Data Licensing |
| 10 | Emerging Topics | None | Presentations |
Grades
Your grade for this course is made up of four different components: Participation, Exercises, Protocol Assignments, and your final Protocol.
-
Participation: See above for participation guidelines. As long as you engage, meet with me, and keep me informed you will get full participation points. (5% of your final grade.)
-
Exercises: Many weeks have a practical exercise component that asks you to apply some concept that is covered in the Chapter or Lecture. You need to complete these by following the directions in each exercise. Completing each exercise is a credit / no-credit mark. Give an earnest effort and you will receive credit. (15% of your final grade.)
-
Protocol Assignments: Most weeks also have a protocol related assignment. If you complete these before our weekly meetings I can give you feedback and help you structure these so that they are useful to your final deliverable. You only need to complete these by including them in your final protocol deliverable. (20% of your final grade)
-
Protocol: The final assignment that is due on or before
Sunday June 06, 2021- The assignment is described in detail on this page. In short, the assignment asks you to envision curating and archiving a set of open data that is focused on a particular topic of interest to a particular audience. This builds upon your experience in developing a protocol in DC I. The final protocol can be turned in a variety of formats, but must include all of the components to be given full credit. (60% of your final grade)
What to do if you find a mistake in this text
I have done my best to customize and adapt Professor Weber’s course content. Since this is my first time preparing the content in this form there will inevitably be mistakes or usability issues. If you find a mistake, an issue, or want to make a recommendation for improvement please send me an email norlab@uw.edu. I promise I want to hear about it.
Acknowledgements
I wouldn’t be teaching this course without the support of Nic Weber and Carole Palmer. A significant portion of the content for this course was originally created by Professor Weber and I want to be fully transparent about that. I couldn’t have done this without his work. I also want to include the acknowledgements from Professor Weber regarding the content he created:
I have had a lot of help putting together these materials. Where possible I have documented these individuals and resources throughout. Some explicit thanks is necessary - Jackson Brown, Andrea Thomer, Peter Organisciak, Katrina Fenlon, and Alex Garnett have contributed ideas for exercises, readings, and reviewed portions of each chapter.
Introduction to Data Curation II
Original Author: Nic Weber
Editing & Updates: Bree Norlander
This introduction provides an overview of the conceptual content that we will engage in for DC II. The goal is to refresh your memory about concepts that were covered in DC I and how we will use these ideas throughout DC II.
Types of Knowledge
This class builds upon some foundational concepts and ideas that were introduced in Data Curation I. The emphasis of DC I was establishing some best (or good enough) practices for managing and preparing data for meaningful reuse. In introducing conceptual foundations in DC I, I also argued that practicing data curators need to acquire two types of knowledge: Declarative and Procedural. If you’ve taken a class with me before you know that I think about this type of framework as being broadly useful for all types of learning. But, this framework is especially relevant for data curation.
To review: Procedural knowledge is how to do something, and declarative knowledge is knowing that something is the case. In other words, understanding something about the factual underpinnings of a concept. Less abstractly - let’s use an example from our (now) everyday lives:
Declaratively we know that a virus outbreak has certain distributions that are the direct result of collective action. If we take no action then there will be an increase in the rate of viral infections. But, if we collectively employ techniques like ‘social distancing’ then the infection rate will remain lower, essential services provided by public health workers will experience less of an impact, and society in general can effectively respond to incidents of viral infection. We probably all remember hearing the phrase ‘flatten the curve’ to refer to this concept - that is taking collective action to decrease the height of a plotted distribution of infections over time.
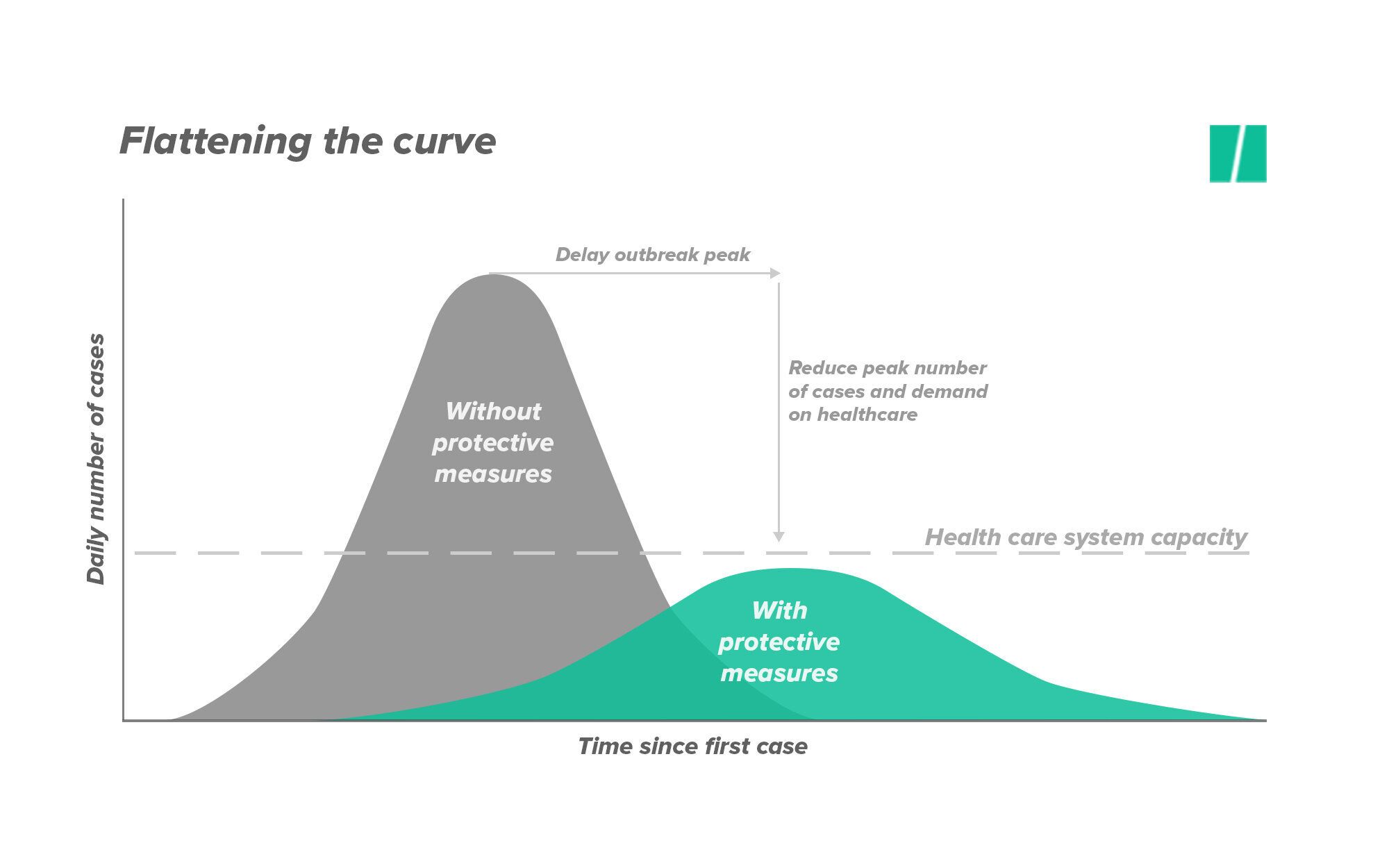
Procedurally - How do we flatten a curve? Well, we employ techniques like social distancing, we wear masks, we wash our hands, we shut down broad sectors of the economy, we adhere to recommendations from the CDC, etc. It is only through knowing how to effectively combat a viral outbreak that we can put our declarative knowledge into practice. And, we can use realtime data to see whether or not we are actually achieving a ‘flattening of the curve’.
Data curation is not so different from this example. We often need to first obtain some declarative knowledge about data and the ways that it was collected, organized, and analyzed. Understanding the intricacies of these issues helps us to understand how we can design effective interventions. In other words, only after we obtain some declarative knowledge about data can we start to employ procedural techniques for preparing data to be managed and used effectively over time.
In DC I we focused a good deal of our time and effort on obtaining declarative knowledge. In DC II we start to tilt more strongly towards practicing and learning procedural techniques for putting this knowledge to work. In this course we will attempt to help you do this in two ways:
- Deepen your declarative knowledge about data, management, organization, and encodings that are specific to the types of open data that we are able to reliably access and use via the web. By focusing in particular on open data we have the ability to practice with and use real world examples.
- Expose you to tools and strategies for employing these skills effectively in curating open data. Putting declarative knowledge to work takes practice, and it gets easier when we are able to abstract away from the particulars of any one context or any one tool’s affordances (and limitations).
Working Definitions
Before we begin diving into the content of DC II, it will help to revisit some definitions that were established in DC I:
Data: Data are various types of digital objects playing the role of evidence. Type and role distinctions have to do with the relational nature of data. A type is rigid (such as a file format) and a role is fluid (it can change given a context). A simple example will help make this clear: I am a person. This is a type. Regardless of any external circumstances I will remain a person. I am also a professor. This is a role that I play. I might, depending on the success of my tenure case, not be a professor in the future. This is simply a professional title that I have for a small amount of time. Data have similar rigid and fluid properties - A tabular dataset will have a type of structure (rows, columns, and values). Unless we take some purposeful action to transform this data it will remain tabular as a type. But, this tabular data might be evidence of some real world phenomena - it might be a set of species occurrence records, the precipitation and temperature of a particular place, etc. This evidential role can shift and change depending on who is using the data, and for what purpose.
FAIR Data: An emerging shorthand description for open research data - that is applicable to any sector - is the concept of F.A.I.R. FAIR data should be Findable, Accessible, Interoperable, and Reusable. We will discuss this concept in a bit more depth throughout this quarter. But, having this shorthand definition of what we try to achieve in doing data curaiton is a helpful reminder for the steps needed to make data truly accessible over the long term.
Data curation: Data curation is the active and ongoing management of data throughout a lifecycle of use, including its reuse in unanticipated contexts. This definition emphasizes that curation is not one narrow set of activities, but is an ongoing process that takes into account both material aspects of data, as well as the surrounding community of users that employ different practices while interacting with data and informaiton infrastructures. In DC II there is a particular emphasis on understanding the minutiae of information infrastructures as they relate to curatorial interventions.
Metadata: Metadata is most simply a set of standardized attribute-value pairs that provide contextual information about an object or artifact. Metadata, at an abstract level, has some features which are helpful for unpacking and making sense of the ways that descriptive, technical, and administrative information become useful for a digital object playing the role of evidence. Metadata can and often does include the following:
- Classes describe concepts that are related to a domain. A domain here means something like an area of application. For example a class of wines would include (or entail) the properties and instances for any wine. Classes are made up of instances, properties, and values (or attributes of an instance).
- Sub-classes refine a class. A sub-class can be a more specific example of a class. Returning to our wine example, a sub-class of wines might be red, white, or rosé. Another sub-class could divide wines into sparkling or non-sparkling. The point is that a sub-class provides some way to divide or simplify the domain that a class is describing.
- Instances are observations or concrete examples of a class or sub-class. For example, in an ontology or metadata scheme describing mammals, my dog
Yaelis an instance of the sub-class Saluki. A Saluki is an instance of the sub-class Canine, which is an instance of a class of Mammals. A class or sub-class instance also has attributes or properties that define it is a member of that class or sub-class. - Attributes are defining features of a class or sub-class, and refer to instances. An instance is a member of a class if it has all of the attributes of that class. For example, a Mammal has certain features (reproductive organs, respiratory system, etc) that define its base or necessary attributes for class membership. Canines as a sub-class have a more specific set of attributes that define membership in that sub-class.
- Relations are the ways that we relate different instances and classes to one another. An instance or a class can be related in one or many ways.
In DC I we also differentiated data and metadata based on its structure.
Structured Metadata is quite literally a structure of attribute and value pairs that are defined by a scheme. Most often, structured metadata is encoded in a machine readable format like XML or JSON. Crucially, structured metadata is compliant with and adheres to a standard that has defined attributes - such as Dublin Core, EML, DDI.
Metadata Schemas define attributes (e.g. what do you mean by “creator” in ecology?); Suggest controls of values (e.g. dates = MM-DD-YYYY); Define requirements for being “well-formed” (e.g. what fields are required for an implementation of the standard); and, Provide example use cases that are satisfied by the standard.
Structured metadata is, typically, differentiated by its documentation role.
- Descriptive Metadata: Tells us about objects, their creation, and the context in which they were created (e.g. Title, Author, Date)
- Technical Metadata: Tells us about the context of the data collection (e.g. the Instrument, Computer, Algorithm, or some other tool that was used in the processing or collection of the data)
- Administrative Metadata: Tells us about the management of that data (e.g. Rights statements, Licenses, Copyrights, Institutions charged with preservation, etc.)
Unstructured Metadata is meant to provide contextual information that is Human Readable. Unstructured metadata often takes the form of contextual information that records and makes clear how data were generated, how data were coded by creators, and relevant concerns that should be acknowledged in reusing these digital objects. Unstructured metadata includes things like codebooks, readme files, or even an informal data dictionary.
A further important distinction that we made about metadata is that it can be applied to both individual items, or collections or groups of related items. We referred to this as a distinction between Item and Collection level metadata.
Expressivity Vs Tractability. One of the key concepts we discussed in DC I is the idea that all knowledge organization activities are a tradeoff between how expressive we make information, and how tractable it is to manage that information. The more expressive we make our metadata, the less tractable it is in terms of generating, managing, and computing for reuse. Inversely, if we optimize our documentation for tractability we sacrifice some of the power in expressing information about attributes that define class membership. The challenge of all knowledge representation and organization activities - including metadata and documentation for data curation - is balancing expressivity and tractability.
Normalization literally means making data conform to a normal schema. Practically, normalization includes the activities needed for transforming data structures, organizing variables (columns) and observations (rows), and editing data values so that they are consistent, interpretable, and match best practices in a field. (Note from Bree: For those of you with statistics and data science experience, note how this differs from statistical normalization techniques. I mention this because I’ve been in conversations where the use of this term has meant different things to different people causing confusion.)
Data Quality: From the ISO 8000 definition we assume data quality are “…the degree to which a set of characteristics of data fulfills stated requirements.” In simpler terms data quality is the degree to which a set of data or metadata are fit for use. Examples of data quality characteristics include completeness, validity, accuracy, consistency, availability and timeliness.
Summary
These basic concepts give us some of the declarative knowledge we need to begin to do data curation work. Over the next ten weeks I will continue to offer working definitions about basic concepts related to DC II readings and topics. It’s important to keep in mind these are ‘working definitions’ - they may have important qualifications or need refinement in any particular context. The point of this long review isn’t to ask you to memorize these concepts, but instead provide something like a ‘term of reference’ or knowledge base that we can continue to refine and improve over the course.
In DC II we are going to tackle topics that help us significantly expand this declarative knowledge. We will look at how to practically decide which type of encoding or representation of data best match the needs of a given community. We will extend the idea of data normalization to include some best practices in creating ‘tidy’ or useful data for computation. We will also look at how to integrate or combine different datasets, such that we can balance something like expressivity and tractability in reusing this data for a new purpose.
I will also introduce some more advanced topics that relate to processes of acquiring, packaging, linking, and representing data such that it can be published to the web.
Exercise
Introduce yourself on the Canvas discussion board. This is not a graded exercise.